Architecture Patterns: Sharding
Sharding is a database architecture pattern that involves dividing a large database into smaller, manageable parts called shards to improve characteristics.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Sharding?
Sharding, a database architecture pattern, involves partitioning a database into smaller, faster, more manageable parts called shards. Each shard is a distinct database, and collectively, these shards make up the entire database. Sharding is particularly useful for managing large-scale databases, offering significant improvements in performance, maintainability, and scalability.
Key Characteristics
Data Distribution: Shards can be distributed across multiple servers, reducing the load on any single server and improving response times.
Horizontal Partitioning: Sharding typically involves horizontal partitioning, where rows of a database table are held separately, rather than dividing the table itself (vertical partitioning).
Independence: Each shard operates independently. Therefore, a query on one shard doesn’t affect the performance of another.
Sharding Types
Horizontal Sharding
Description: Horizontal sharding, also known as data sharding, involves dividing a database table across multiple databases or database instances. Each shard contains the same table schema but holds a different subset of the data, typically split based on a shard key. The division is such that each row of the table is stored in only one shard.
Use Case: Ideal for applications with a large dataset where data rows can be easily segmented, such as splitting customer data by geographic regions or user IDs. This method is highly effective in balancing the load and improving query performance as it reduces the number of rows searched in each query.

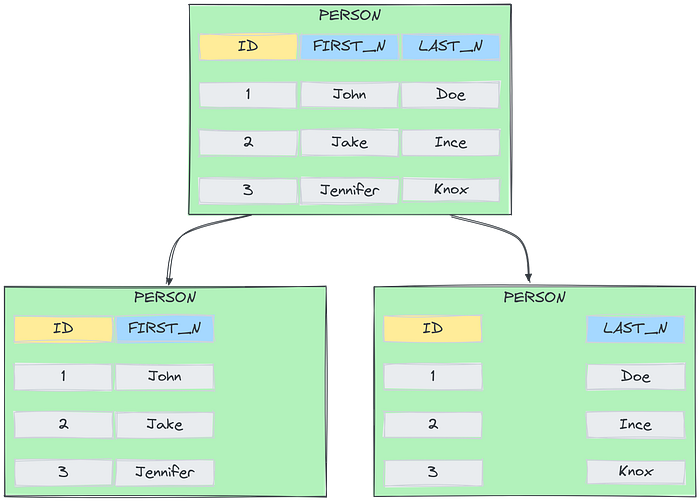
Vertical Sharding
Description: Involves splitting a database into smaller subsets, where each shard holds a subset of the database tables. This method is often used to separate a database into smaller, more manageable parts, with each shard dedicated to specific tables or groups of tables related to particular aspects of the application.
Use Case: Suitable for databases where certain tables are accessed more frequently than others, reducing the load on heavily queried tables. For example, in a web application, user authentication data could be stored in one shard, while user activity logs are stored in another, optimizing the performance of frequently accessed tables.
Sharding Strategies
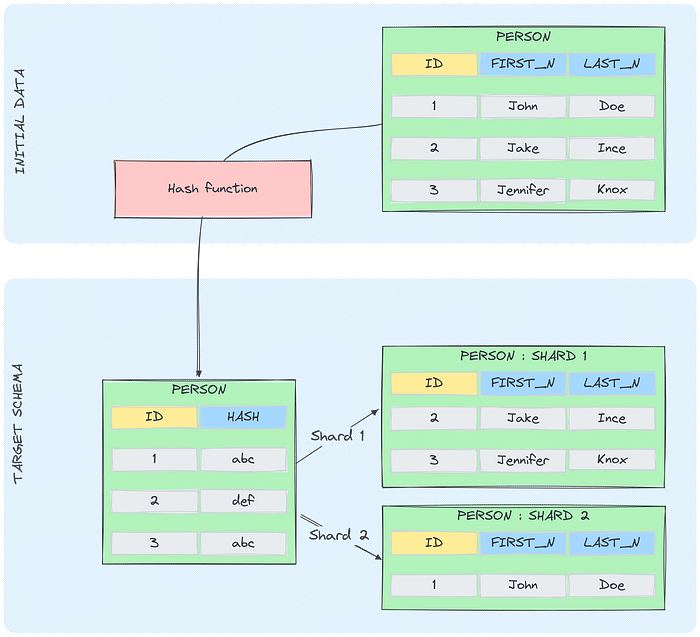
Hash-Based Sharding
Description: Involves using a hash function to determine the shard for each data record. The hash function takes a shard key, typically a specific attribute or column in the dataset, and returns a hash value which is then used to assign the record to a shard.
Use Case: Ideal for applications where uniform distribution of data is critical, such as in user session storage in web applications.
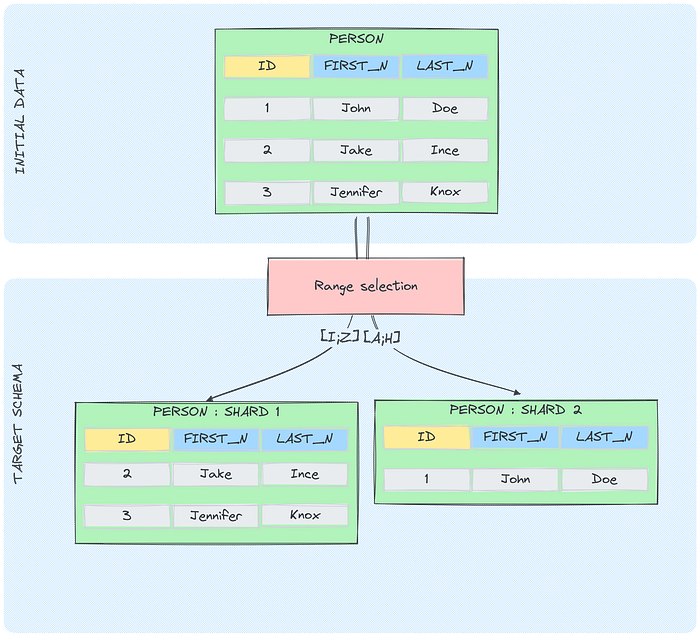
Range-Based Sharding
Description: This method involves dividing data into shards based on ranges of a shard key. Each shard holds data for a specific range of values.
Use Case: Suitable for time-series data or sequential data, such as logs or events that are timestamped.
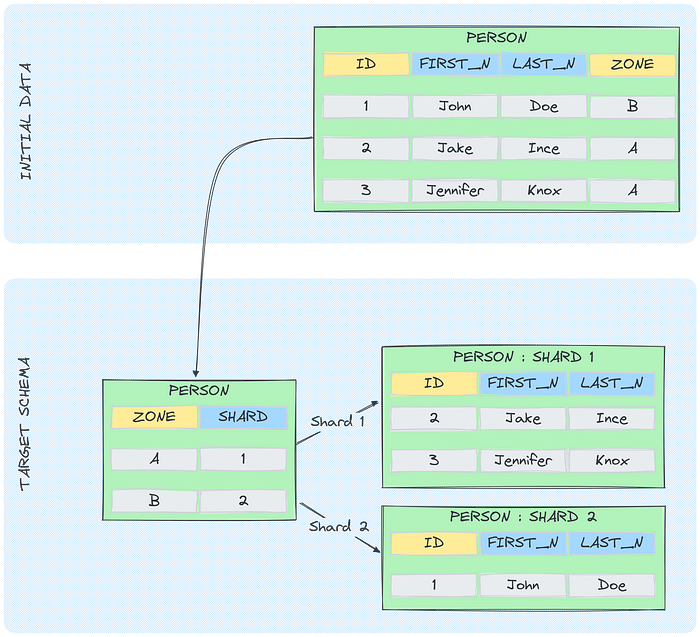
Directory-Based Sharding
Description: Uses a lookup service or directory to keep track of which shard holds which data. The directory maps shard keys to shard locations.
Use Case: Effective in scenarios where the data distribution can be non-uniform or when dealing with complex criteria for data partitioning.
Geo-Sharding
Description: Data is sharded based on geographic locations. Each shard is responsible for data from a specific geographic area.
Use Case: Ideal for services that require data locality, like content delivery networks or location-based services in mobile applications.
Benefits
Scalability: By distributing data across multiple machines, sharding allows for horizontal scaling, which is more cost-effective and manageable than vertical scaling (upgrading existing hardware).
Performance Improvement: Sharding can lead to significant improvements in performance. By dividing the database, it ensures that the workload is shared, reducing the load on individual servers.
High Availability: Sharding enhances availability. If one shard fails, it doesn’t bring down the entire database. Only a subset of data becomes unavailable.
Trade-Offs
Complexity in Implementation: Sharding adds significant complexity to database architecture and application logic, requiring careful design and execution.
Data Distribution Challenges: Requires a strategic approach to data distribution. Poor strategies can lead to unbalanced servers, with some shards handling more load than others.
Join Operations and Transactions: Join operations across shards can be challenging and may degrade performance. Managing transactions spanning multiple shards is complex.
Back to Standard Architecture Complexity: Reverting a sharded database back to a non-sharded architecture can be extremely challenging and resource-intensive. This process involves significant restructuring and data migration efforts.
Conclusion
Sharding is an effective architectural pattern for managing large-scale databases. It offers scalability, improved performance, and high availability. However, these benefits come at the cost of increased complexity, particularly in terms of implementation and management. Effective sharding requires a thoughtful approach to data distribution and a deep understanding of the application’s data access patterns. Despite its challenges, sharding remains a crucial tool in the arsenal of database architects, particularly in the realms of big data and high-traffic applications. As data continues to grow in volume and significance, sharding will continue to be a vital strategy for efficient and effective database management.
Published at DZone with permission of Pier-Jean MALANDRINO. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments