Unlocking the Power Duo: Kafka and ClickHouse for Lightning-Fast Data Processing
Explore integration strategies for Kafka and ClickHouse, focusing on various methodologies like Kafka Engine, Kafka Connect, DoubleCloud Transfer, and ClickPipes.
Join the DZone community and get the full member experience.
Join For FreeImagine the challenge of rapidly aggregating and processing large volumes of data from multiple point-of-sale (POS) systems for real-time analysis. In such scenarios, where speed is critical, the combination of Kafka and ClickHouse emerges as a formidable solution. Kafka excels in handling high-throughput data streams, while ClickHouse distinguishes itself with its lightning-fast data processing capabilities. Together, they form a powerful duo, enabling the construction of top-level analytical dashboards that provide timely and comprehensive insights. This article explores how Kafka and ClickHouse can be integrated to transform vast data streams into valuable, real-time analytics.
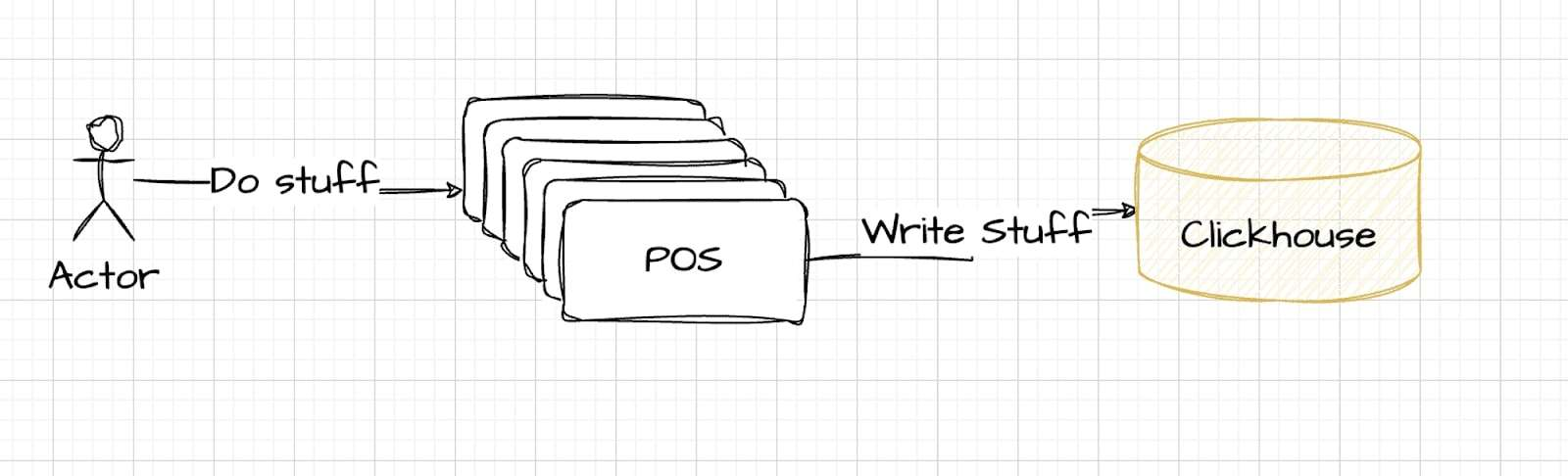
This diagram depicts the initial, straightforward approach: data flows directly from POS systems to ClickHouse for storage and analysis. While seemingly effective, this somewhat naive solution may not scale well or handle the complexities of real-time processing demands, setting the stage for a more robust solution involving Kafka.
Understanding Challenges With Data Insertion in ClickHouse
The simple approach may lead you to a common pitfall or first “deadly sin” when starting with ClickHouse (for more details, see Common Getting Started Issues with ClickHouse). You'll likely encounter this error during data insertion, visible in ClickHouse logs, or as a response to an INSERT request. Grasping this issue requires knowledge of ClickHouse's architecture, specifically the concept of a “part.”
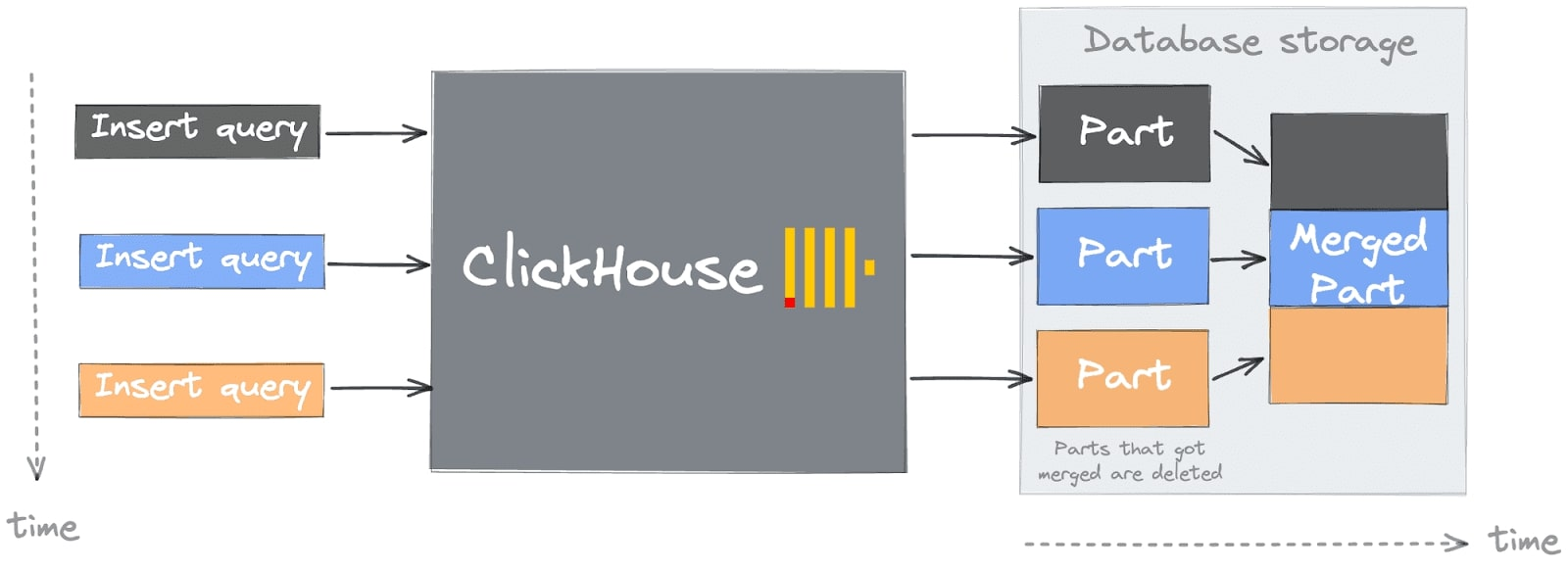
Ingesting data into ClickHouse is most effective when managed with precision, leveraging both speed and parallelism. The optimal process, as illustrated, involves batched insertions coordinated by a central system rather than individual, uncontrolled streams of data:
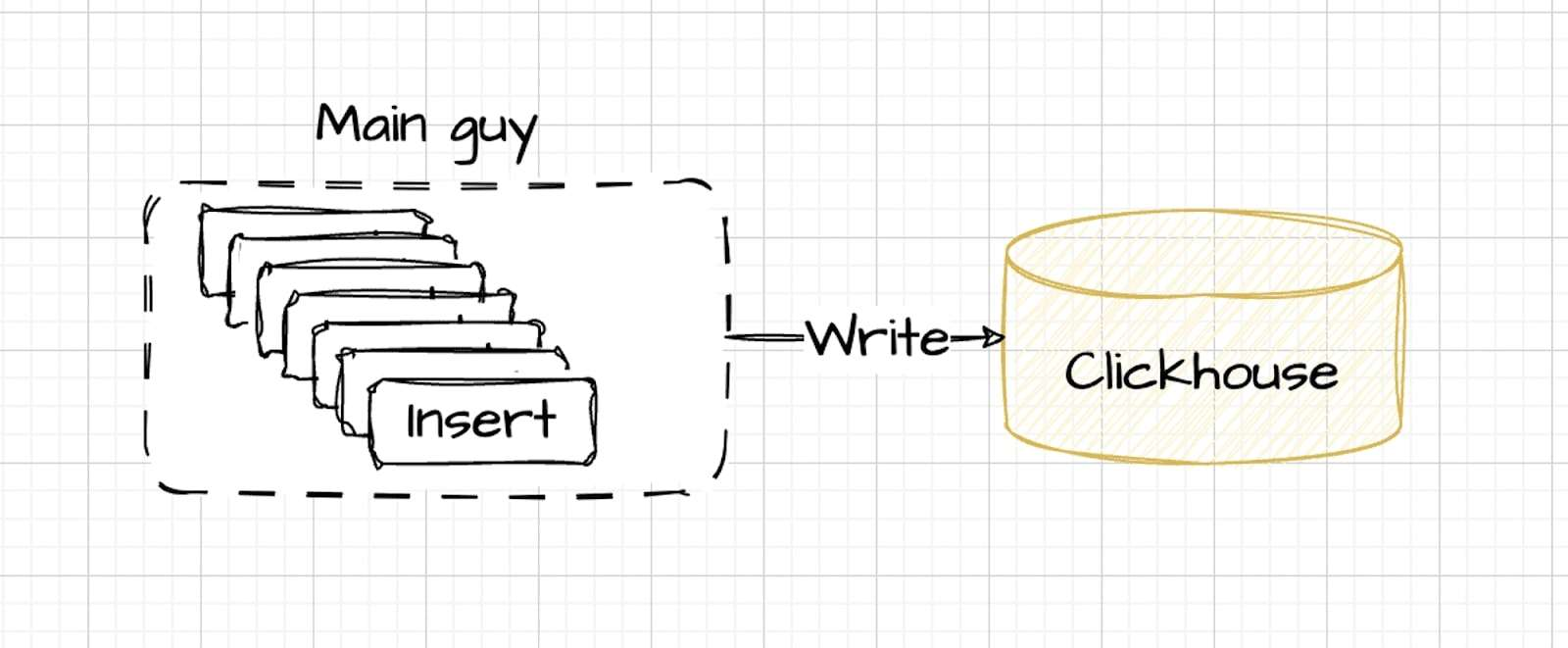
In the optimal setup, data is inserted by a primary controller that manages the flow, adjusting speed dynamically while maintaining controlled parallelism. This method ensures efficient data processing and is in line with ClickHouse's optimal performance conditions.
That's why, in practice, it's common to introduce a buffer before ClickHouse:
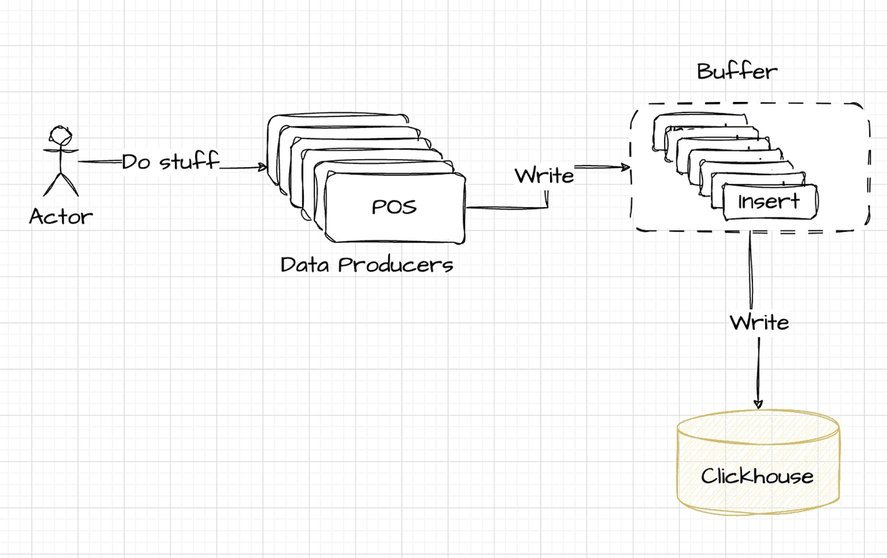
Kafka now enters the architecture as the preferred solution for data buffering. It effortlessly bridges the gap between the data producers and ClickHouse, offering a robust intermediary that enhances data handling. Here's how the revised architecture integrates Kafka:
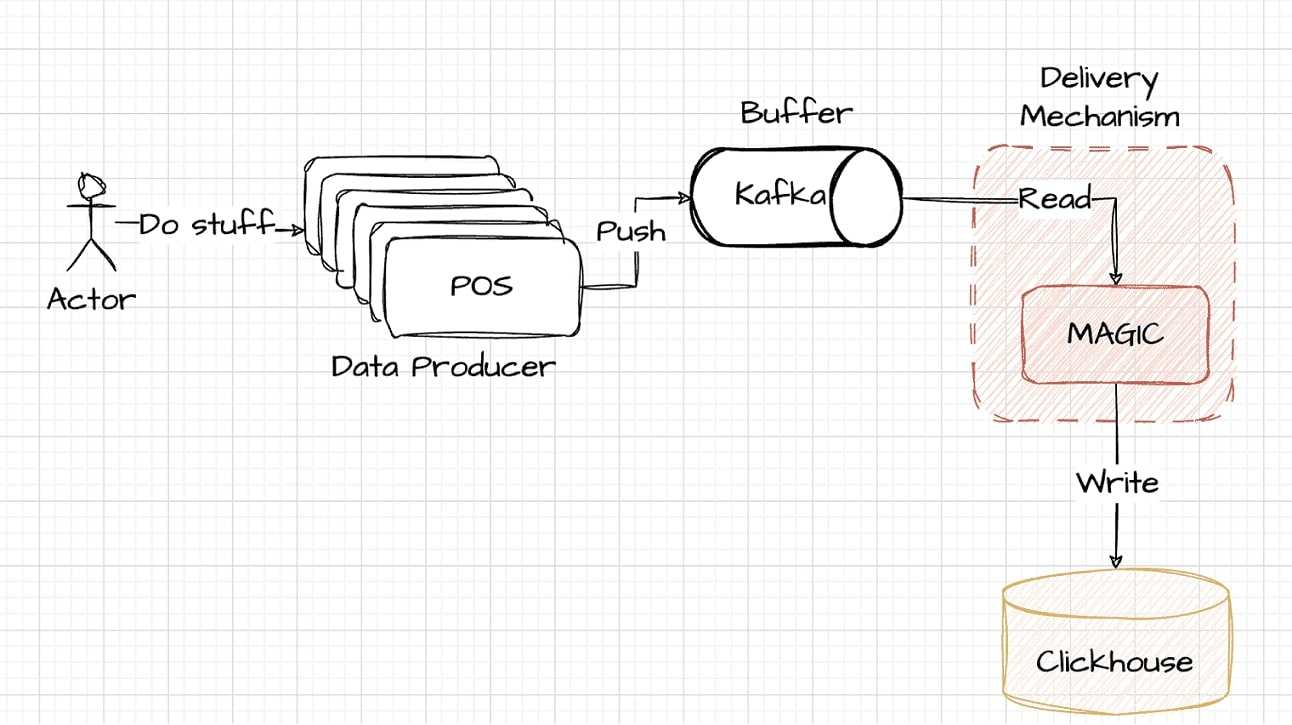
The integration of Kafka requires additional coding to funnel data from POS systems and then to ClickHouse. This element of the architecture, while powerful and scalable, introduces complexity that we'll explore in more detail later in the article.
Data Transfer From Kafka to ClickHouse
The critical stages in delivering data from Kafka to ClickHouse involve reading Kafka topics, transforming data into ClickHouse-compatible formats, and writing this formatted data into ClickHouse tables. The trade-off here lies in deciding where to perform each stage.
Each stage has its own resource demands:
- Reading stage: This initial phase consumes CPU and network bandwidth to pull in data from Kafka topics.
- Transformation process: Transforming the data demands CPU and memory usage. It's a straightforward resource-utilization phase, where computational power reshapes the data to fit ClickHouse's specifications.
- Writing stage: The final act involves writing data into ClickHouse tables, which also requires CPU power and network bandwidth. It's a routine process, ensuring the data finds its place in ClickHouse's storage with allocated resources.
When integrating, it's essential to balance these resource uses.
Now, let's examine the various methodologies for linking Kafka with ClickHouse.
ClickHouse’s Kafka Engine
Leverage the Kafka engine within ClickHouse to directly ingest data into your tables. The high-level process is visually represented in the accompanying diagram:
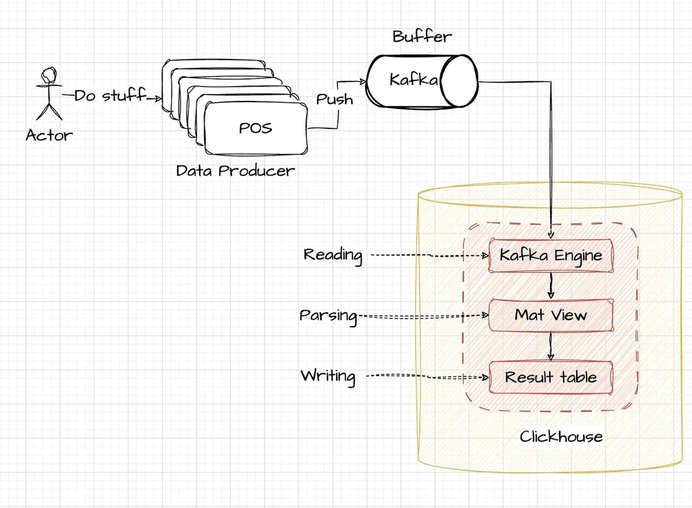
Considering this scenario, the POS terminals are designed to output data in a structured JSON format, with each entry separated by a new line. This format is typically well-suited for log ingestion and processing systems.
{"user_ts": "SOME_DATE", "id": 123, "message": "SOME_TEXT"}
{"user_ts": "SOME_DATE", "id": 1234, "message": "SOME_TEXT"}To set up the Kafka Engine in ClickHouse, we begin by creating a topic wrapper within ClickHouse using the Kafka Engine. This is outlined in the provided example file: example kafka_stream_engine.sql
-- Clickhouse queue wrapper
CREATE TABLE demo_events_queue ON CLUSTER '{cluster}' (
-- JSON content schema
user_ts String,
id UInt64,
message String
) ENGINE = Kafka SETTINGS
kafka_broker_list = 'KAFKA_HOST:9091',
kafka_topic_list = 'TOPIC_NAME',
kafka_group_name = 'uniq_group_id',
kafka_format = 'JSONEachRow'; -- FormatIn this query, three things are established:
- Schema of data: A ClickHouse table structure containing three defined columns;
- Data format: The format specified as ‘JSONEachRow,’ suitable for parsing newline-delimited JSON data;
- Kafka configuration: The settings for the Kafka host and topic are included to link the data source with ClickHouse.
The next step in the setup involves defining a target table in ClickHouse that will store the processed data:
/example_projects/clickstream/kafka_stream_engine.sql#L12-L23
-- Table to store data
CREATE TABLE demo_events_table ON CLUSTER '{cluster}' (
topic String,
offset UInt64,
partition UInt64,
timestamp DateTime64,
user_ts DateTime64,
id UInt64,
message String
) Engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/{database}/demo_events_table', '{replica}')
PARTITION BY toYYYYMM(timestamp)
ORDER BY (topic, partition, offset);This table will be structured using the ReplicatedMergeTree engine, providing robust data storage capabilities. In addition to the base data columns, the table will include additional columns derived from the metadata provided by Kafka Engine, allowing for enriched data storage and query capabilities.
/example_projects/clickstream/kafka_stream_engine.sql#L25-L34
-- Delivery pipeline
CREATE MATERIALIZED VIEW readings_queue_mv TO demo_events_table AS
SELECT
-- kafka engine virtual column
_topic as topic,
_offset as offset,
_partition as partition,
_timestamp as timestamp,
-- example of complex date parsing
toDateTime64(parseDateTimeBestEffort(user_ts), 6, 'UTC') as user_ts,
id,
message
FROM demo_events_queue;The final step in the integration process is to set up a materialized view within ClickHouse that bridges the Kafka Engine table with your target table. This materialized view will automate the transformation and insertion of data from the Kafka topic into the target table, ensuring that the data is consistently and efficiently processed and stored.
Together, these configurations facilitate a robust pipeline for streaming data from Kafka into ClickHouse:
SELECT count(*)
FROM demo_events_table
Query id: f2637cee-67a6-4598-b160-b5791566d2d8
┌─count()─┐
│ 6502 │
└─────────┘
1 row in set. Elapsed: 0.336 sec.When deploying all three stages—reading, transforming, and writing—within ClickHouse, this setup is generally more manageable for smaller datasets. However, it might not scale as effectively for larger workloads. Under heavy load, ClickHouse typically gives preference to query operations, which could lead to increased latency in data delivery as resource competition arises. This is an important consideration when planning for high-volume data handling.
While the Kafka Engine integration is functional, it presents several challenges:
- Offset management: Malformed data in Kafka can stall ClickHouse, requiring manual intervention to delete offsets, a task that can be demanding.
- Limited observability: Since operations are internal to ClickHouse, monitoring is more complex and relies heavily on analyzing ClickHouse logs to understand system behavior.
- Scalability concerns: Executing parsing and reading inside ClickHouse could hinder scaling during high loads, which might lead to resource contention issues.
Utilizing Kafka Connect
Kafka Connect offers a different approach by reallocating the complexities of data management from ClickHouse to Kafka.
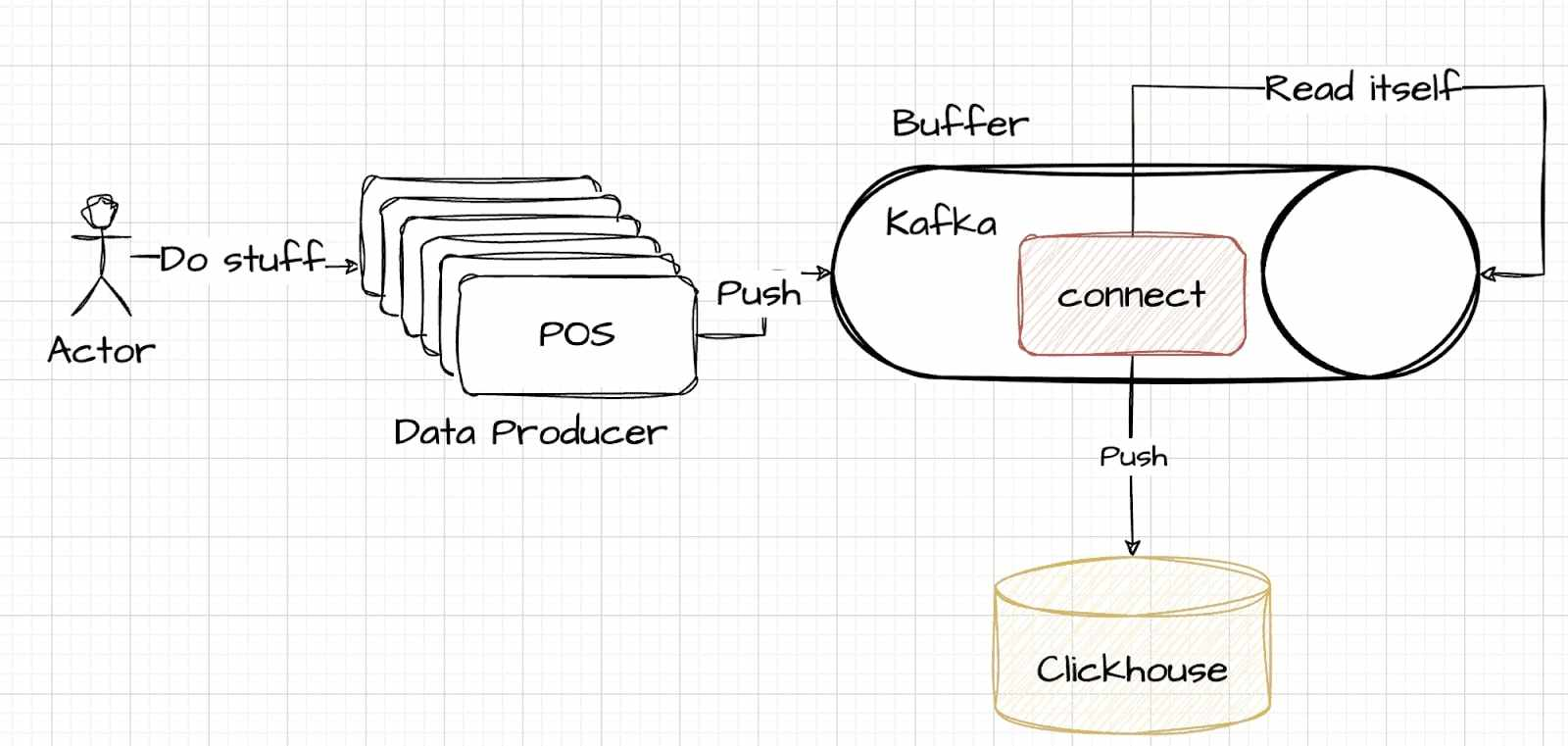
This strategy involves a careful decision about where to handle the data management intricacies. In this model, tasks such as reading, parsing, and writing are managed within Kafka Connect, which operates as part of the Kafka system. The trade-offs in this approach are similar but involve shifting the processing burden from the data storage side to the buffering side. An illustrative example is provided here to demonstrate how to establish this connection.
Opting for an External Writer
The External Writer approach represents a premium solution, offering superior performance for those who are ready to invest more. It typically involves an external system responsible for data handling, positioned outside of both the buffer (Kafka) and storage (ClickHouse) layers. This setup might even be co-located with the data-producing sources, offering a high level of efficiency and speed. The following diagram simplifies this configuration, showcasing how external writers can be integrated into the data pipeline:
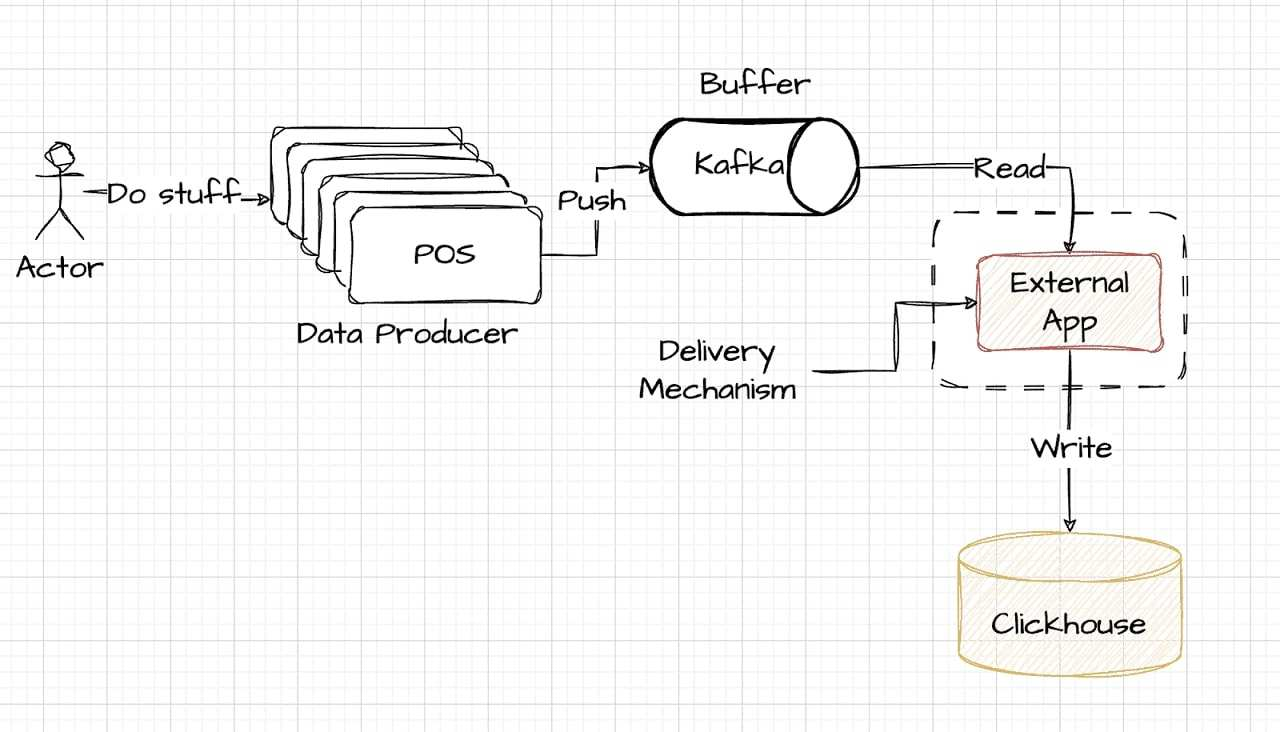
External Writer via DoubleCloud
For implementing an external writer approach using DoubleCloud Transfer, the setup involves two primary components: source and destination endpoints, along with the transfer mechanism itself. This configuration is efficiently managed using Terraform. A key element in this setup is the parser rule for the Source endpoint, which is critical for accurately interpreting and processing the incoming data stream. The details of this configuration are outlined here:
/example_projects/clickstream/transfer.tf#L16-L43
parser {
json {
schema {
fields {
field {
name = "user_ts"
type = "datetime"
key = false
required = false
}
field {
name = "id"
type = "uint64"
key = false
required = false
}
field {
name = "message"
type = "utf8"
key = false
required = false
}
}
}
null_keys_allowed = false
add_rest_column = true
}
}The parser configuration in DoubleCloud Transfer plays a similar role to the DDL specifications in ClickHouse. It's crucial for ensuring the correct interpretation and processing of incoming data. Once the source endpoint is established, the next step is to add the target database, which is typically more straightforward:
/example_projects/clickstream/transfer.tf#L54-L63
clickhouse_target {
clickhouse_cleanup_policy = "DROP"
connection {
address {
cluster_id = doublecloud_clickhouse_cluster.target-clickhouse.id
}
database = "default"
user = "admin"
}
}Finally, link them together into a transfer:
/example_projects/clickstream/transfer.tf#L67-L75
resource "doublecloud_transfer" "clickstream-transfer" {
name = "clickstream-transfer"
project_id = var.project_id
source = doublecloud_transfer_endpoint.clickstream-source[count.index].id
target = doublecloud_transfer_endpoint.clickstream-target[count.index].id
type = "INCREMENT_ONLY"
activated = true
}With the completion of these steps, your data delivery system utilizing DoubleCloud Transfer is now operational. This setup ensures a seamless flow of data from the source to the target database, effectively managing the entire process.
DoubleCloud's EL(t) engine, Transfer, integrates Queue Engine to ClickHouse delivery, tackling common challenges:
- Automated offset management: Transfer automates the handling of corrupt data through unparsed tables, minimizing the need for manual offset management.
- Enhanced observability: Unlike limited monitoring in ClickHouse, Transfer provides dedicated dashboards and alerts for real-time insights into delivery metrics like data lag, row counts, and bytes delivered.
- Dynamic scalability: Transfer's delivery jobs, hosted on Kubernetes, EC2, or GCP, allow for scalable operations independent of ClickHouse.
Transfer additionally provides out-of-the-box features to enhance its functionality:
- Automatic schema evolution: Automatically synchronizes backward-compatible schema changes with the target storage.
- Automatic dead-letter queue: Efficiently manages corrupt data by redirecting it to a designated Dead-Letter Queue (DLQ) within the ClickHouse table.
External Writer via Clickpipes
ClickPipes offers a simplified and efficient solution for ingesting data from various sources. Its user-friendly interface allows for quick setup with minimal effort. Engineered for high-demand scenarios, ClickPipes boasts a robust, scalable architecture that delivers consistent performance and reliability. While it shares similarities with DoubleCloud Transfer in terms of functionality, ClickPipes does not support automatic schema evolution. For detailed setup instructions, a comprehensive guide is available here.
Conclusion
In this article, we've explored various methodologies for integrating Kafka with ClickHouse, focusing on options like the Kafka Engine, Kafka Connect, DoubleCloud Transfer, and ClickPipes. Each of these approaches offers unique strengths and considerations tailored to different data processing requirements and operational scales. From resource management to system scalability, the selection of the right approach is crucial for optimal data handling.
To further explore the synergy of Kafka and ClickHouse, consider diving into the DoubleCloud stack. They provide insightful Terraform examples that can be a great starting point for those looking to implement these powerful tools in their data processing workflows. For more detailed guidance, check out their Terraform exemplars.
Opinions expressed by DZone contributors are their own.
Comments